
Luke Posey, Product Manager
Apr 21, 2025

The world runs on PDFs.
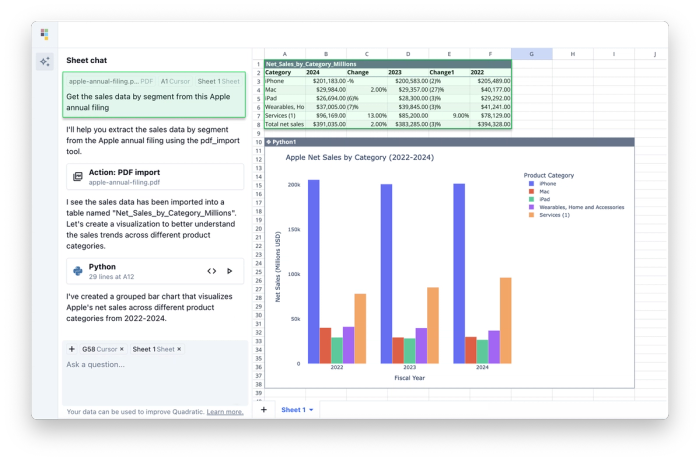
We’ve seen numerous use cases in Quadratic that would greatly benefit from document understanding. In particular, finance and accounting professionals have noted the usefulness of the potential for this feature for tasks like invoice data capture. We’ve talked to some users who have found Quadratic AI to be so powerful, that it was worth it to them to copy-paste thousands of lines of PDFs individually by hand and into AI Chat to get processed into the spreadsheet. We built this PDF table extraction feature with those users in mind, hoping to turn what would take many prompts for a PDF to spreadsheet conversion into a single decisive extraction step.
Model selection
At Quadratic, we’re keeping our ear to the ground to always identify the current state-of-the-art (SOTA) AI models and best practices. We’re seeing Gemini 2.5 Pro among the most powerful models for scalable PDF data extraction. With a huge context window, SOTA performance, and impressive speed over huge documents, it became our choice.
In our research, we saw other solid model options, but some are prohibitively priced, and others are too difficult to integrate; our ultimate goal is to provide our users with SOTA performance without needing to pass on high costs. We’re always open to swapping out our existing choice for superior models, both closed and open source, as they get released.
How it works
Whenever a PDF is dropped into the chat, a tool call can be made by the main model to pass the PDF to our PDF model, who processes the PDF and returns the results in tabular format to the sheet.
This approach ensures a PDF in the chat doesn’t automatically mean the chat’s context becomes bloated with the entire PDF. A tool call can always be made to extract more information from the PDF as desired. The necessary content to extract is targeted based on the prompt. Extra information is not left in context and requires further tool calls as further prompts are submitted.
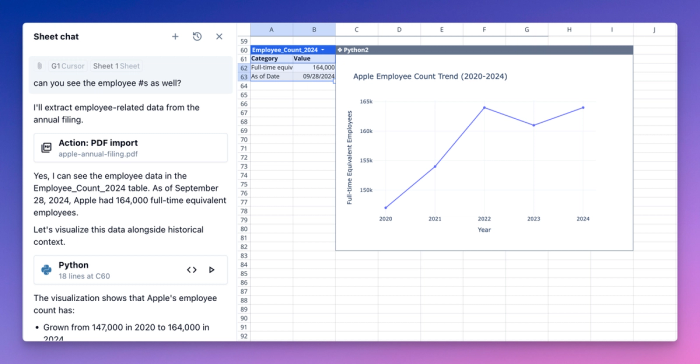
Because this is all part of our chat, the AI can also follow up with natural chat-based analytics, often unprompted. Note in the above example how it decided that a chart plotting the employee trajectory based on the PDF numbers made sense in that context.
Here’s a sampling of the instructions from our PDF Import tool. We note that explicit and sometimes repeated instructions draw the best performance out of our model’s ability to respond correctly.
You are a pdf file importing tool which is tasked to extract data from PDF files to the spreadsheet as structured data tables which can be used for analysis or visualization.\n
Always stay true to the data in the original PDF file and create tables that accurately represent the information in the PDF. Never make up data or add extra information that is not present in the PDF.\nOur approach in this case, like in any case across our product, is to architect so that as more performant models are released, we can easily drop in the latest release from our current provider, competitor providers, or a custom fine-tuned model. We’ve found users are mostly apathetic to model choice; they want whatever model best solves their use case. We used to support many model choices but found that the default model choice received nearly 100% of usage.
Image understanding
With images, we took a different approach. Less concerned by context bloat from images, images go straight into the context and stay in the chat.
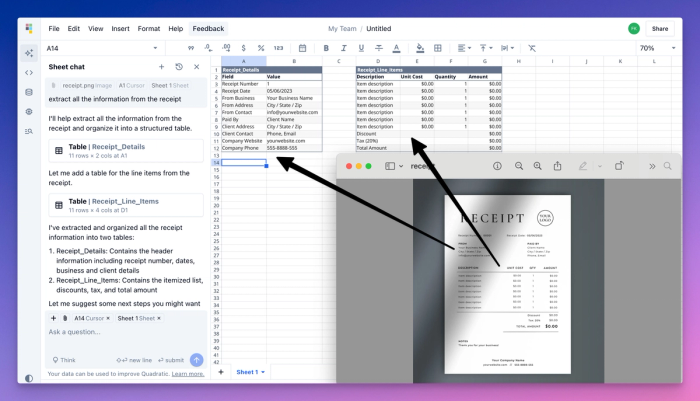
Aside from extracting information from images, we find the most useful part of image support is helping the AI understand what it has placed in the sheet for debugging.
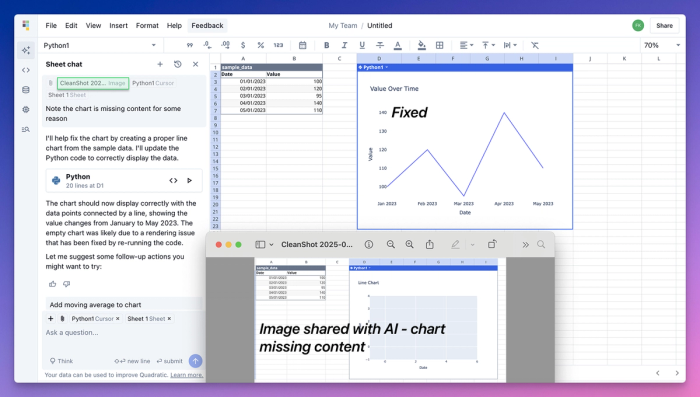
One can imagine many similar use cases, from debugging incorrect values to prettifying charts to improving sheet layouts.
In closing
With Quadratic, we want you to be able to drive insights as fast as possible without needing to take tons of manual steps to get your data sources into the spreadsheet.
Get started with PDF data extraction here, and let us know what you think.