Table of contents
- The challenge: Why managing unstructured data is critical for compliance
- A tactical workflow to extract and standardize data
- The "trust" factor: Human-in-the-loop & confidence scores
- Creating an audit-ready output
- Summary: The analyst-led data pipeline
- Use Quadratic to manage unstructured compliance data
For the modern compliance analyst, the daily reality often involves drowning in documents. You are likely staring at a queue of PDFs, email threads, regulatory filings, and messy log files. The data you need to do your job—transaction dates, counterparty names, risk clauses—is trapped inside these files. It does not fit neatly into database rows, and the process of getting it there usually involves hours of mind-numbing copy-pasting.
This is the core problem of unstructured data management in the compliance sector. For years, the industry has treated this largely as a storage problem: where do we save these files so they are compliant? But for the analyst on the ground, storage is irrelevant if the data inside those files is inaccessible.
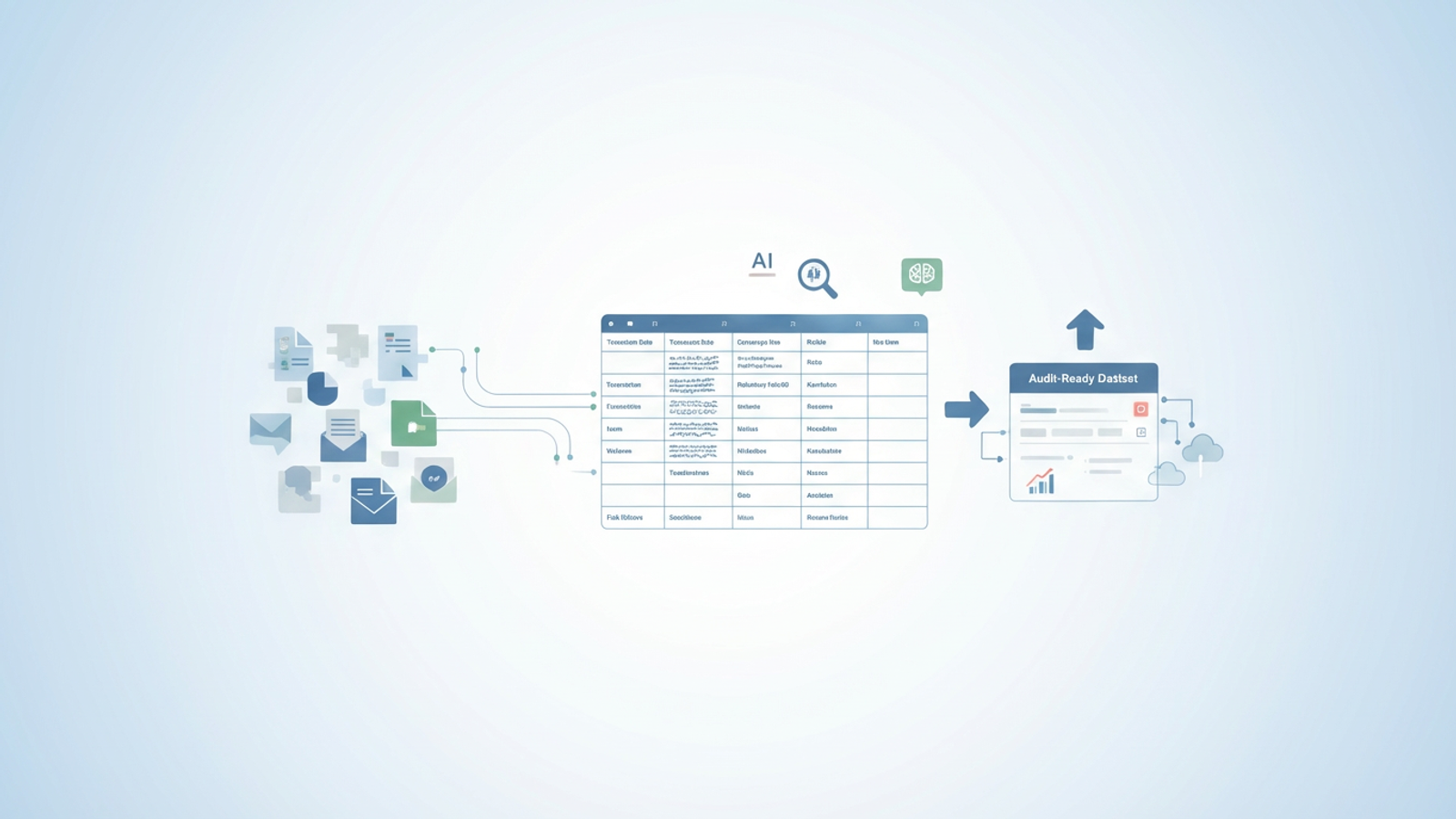
Effective management is not just about archiving; it is about transforming chaos into a standardized, audit-ready dataset. Instead of waiting months for IT to build a complex extraction pipeline, analysts can now use tools like Quadratic to build their own tactical workflows. By ingesting raw text, applying AI extraction, and enforcing a strict schema, you can turn a folder full of "dark data" into a clean table that is ready for analysis.
The challenge: Why managing unstructured data is critical for compliance
In the context of compliance and risk operations, unstructured data management refers to the process of identifying, capturing, and organizing data that lacks a pre-defined data model. This includes Know Your Customer (KYC) documents, legal contracts, internal chat logs, and vendor emails.
The stakes are high because approximately 80% to 90% of enterprise data is unstructured. When this data is left unmanaged, it becomes "dark data"—information that the organization collects but fails to utilize. In compliance, dark data is a liability. It might hide evidence of fraud, a breach of contract, or a regulatory violation that goes unnoticed until an external auditor finds it.
However, manually reviewing every document is impossible at scale. This creates a dangerous gap. Many traditional unstructured data management solutions attempt to fill this gap with "black box" automation. You feed documents in, and the software spits data out. But for a risk officer, "hoping" the software got it right is not a strategy. You need verification, transparency, and a way to ensure that the data you are reporting on is accurate.
A tactical workflow to extract and standardize data
Rather than relying on rigid enterprise software, you can use Quadratic to build a transparent, analyst-led pipeline. Because Quadratic combines the familiarity of a spreadsheet with the power of AI and Python, it allows you to manage the extraction process cell by cell.
Step 1: Centralize and ingest
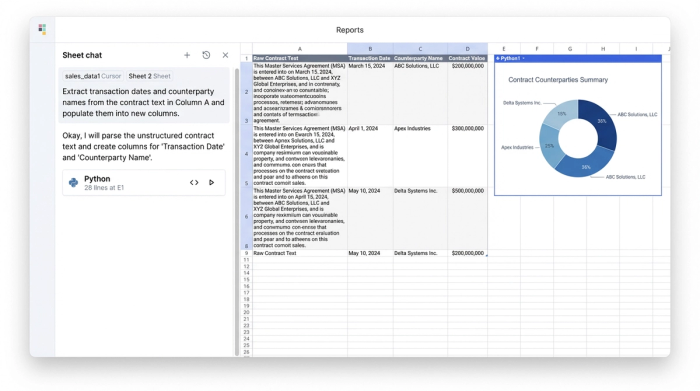
The first step is bringing the raw data into a workable environment. In a standard spreadsheet, pasting a five-page contract into a single cell usually breaks the interface. Quadratic is built to handle high-density data. You can copy raw text blobs from PDFs, emails, or JSON dumps and paste them directly into the grid. Alternatively, you can connect directly to your data sources using Python to pull in the raw text automatically. This places your source material right next to your extraction columns, keeping the context visible.
Step 2: AI-powered entity extraction
Once the raw text is in the grid, you can use AI formulas to parse it. Instead of writing complex Regular Expressions (RegEx) that break whenever a document format changes, you can use natural language prompts to extract specific entities. For example, you might set up columns for "Transaction Date," "Counterparty Name," and "Risk Clause." You then instruct the AI to look at the raw text in column A and extract the relevant details into these respective columns.
Step 3: Enforcing a schema
Extraction is only half the battle; standardization is what makes the data useful. A human reader knows that "Sept 1st, 2024" and "01-09-2024" are the same date, but a database does not. To effectively manage unstructured data, you must enforce a schema. You can instruct the AI or use Python scripts within Quadratic to normalize these outputs into a single ISO format (YYYY-MM-DD) or standardize naming conventions (e.g., converting "LLC" and "L.L.C." to a single standard). This turns vague text into queryable data.
The "trust" factor: Human-in-the-loop & confidence scores
A major hesitation analysts have with unstructured data management tools is the fear of AI hallucinations. In compliance, reporting a false positive or missing a critical risk factor can have legal consequences. Automation is necessary for speed, but human oversight is necessary for trust.
Quadratic solves this by keeping the human in the loop. You should not just ask the AI for the data; you should ask it for a confidence score.
When building your extraction workflow, add a column that asks the AI to rate its confidence in its own extraction on a scale of 0 to 100. If the document is blurry or the text is ambiguous, the confidence score will drop. You can then apply conditional formatting to highlight any cell where confidence is below 80% in red.
This creates a review queue. Instead of spot-checking random rows, the analyst can sort the sheet by confidence score. You instantly see the rows where the AI struggled. Because you are in a spreadsheet interface, you can manually correct the data right there in the cell. This hybrid approach—AI for the bulk work, humans for the edge cases—ensures high accuracy without sacrificing speed.
Creating an audit-ready output
Once the data has been extracted, standardized, and validated, it is no longer "unstructured." It is now a structured, queryable dataset residing in your grid.
This clean data is ready for downstream use. You can use Quadratic’s native SQL or Python features to query this new table, identifying trends or flagging violations. You can visualize the data using built-in charting tools to present findings to stakeholders, or simply export the clean CSV for submission to regulatory bodies.
This workflow offers a significant advantage over legacy unstructured data lifecycle management software vendors. Implementing a vendor solution can take months of procurement and IT integration. By the time the software is ready, the regulatory requirements may have changed. By building your own pipeline in a flexible tool like Quadratic, you gain immediate control over your data and the agility to adapt your schema whenever new regulations arise.
Summary: The analyst-led data pipeline
Effective unstructured data management is about accessibility and trust. It moves the focus from simply storing files to actually using the information contained within them. By following a tactical workflow—Import, Extract, Validate, and Report—compliance teams can turn their biggest headache into their most valuable asset.
The workflow is straightforward:
1. Ingest raw text into the grid.
2. Use AI to extract and standardize entities.
3. Use confidence scores to direct human attention where it is needed most.
4. Generate audit-ready reports from the finalized table.
You do not need to wait for a massive digital transformation project to get control of your documents. You can start building this extraction pipeline in Quadratic today with your own sample documents, turning a backlog of files into clear, actionable insights.
Use Quadratic to manage unstructured compliance data
- Ingest diverse unstructured compliance documents (like PDFs, emails, and log files) directly into a flexible grid, eliminating manual copy-pasting.
- Automate extraction of critical entities such as transaction dates, counterparty names, and risk clauses using natural language AI prompts.
- Standardize extracted data into consistent, audit-ready formats (e.g., ISO dates, uniform naming) using AI or Python.
- Leverage AI confidence scores to identify and prioritize data needing human review, ensuring accuracy for compliance reporting.
- Correct and refine extracted data directly within the familiar spreadsheet interface, maintaining full transparency and control.
- Transform raw text into queryable, structured datasets for rapid analysis, reporting, and adapting to new regulations.
Ready to transform your compliance data? Try Quadratic.