Table of contents
Conducting systematic reviews and meta-analyses demands rigorous data synthesis. However, the most significant bottleneck researchers face is almost always getting data out of unstructured PDF documents. Academic standards, such as the Cochrane guidelines, require the meticulous collection of study characteristics, participant details, interventions, outcomes, and bias assessments.
While the methodology for evaluating this information is incredibly well-documented, the actual execution remains painfully manual. This article explores how to bridge strict academic standards with modern spreadsheet automation to streamline clinical trial data extraction.
The core pillars of rigorous data extraction
To capture high-quality evidence, systematic review data extraction must follow strict protocols. Researchers must categorize findings into standard buckets to ensure uniformity across studies. The critical components of data collection for evidence synthesis include:
- Study Characteristics: Capturing trial design, geographic location, and publication details.
- Participant Details: Recording demographics, sample sizes, and inclusion or exclusion criteria.
- Intervention Details: Documenting dosages, delivery methods, and control group parameters.
- Outcomes: Extracting primary and secondary endpoints, along with their respective measurement scales.
- Risk of Bias: Assessing methodological flaws, blinding protocols, and allocation concealment.
During this process, researchers constantly battle data heterogeneity and missing variables. Standardizing these formats is vital for accurate downstream statistical modeling, particularly when preparing data for random-effects models.
The bottleneck: manual processes vs. modern tooling
The traditional approach to research synthesis relies heavily on static Excel templates and manual data entry from deeply nested PDF reports. This method introduces severe limitations to the research lifecycle.
Relying on human transcription leads to high error rates and makes it incredibly difficult to reach a consensus among multiple reviewers. Furthermore, manually hunting for specific variables across dozens of dense academic papers is a massive time sink. The clinical research field desperately needs automated data extraction tools and dynamic environments to evaluate tabular data quality and accelerate the review process.
A better workflow: automating Clinical Trial Data Extraction with Quadratic
Transitioning to a smarter process means rethinking how we handle clinical trial data extraction from the ground up. Instead of relying on rigid, static grids, modern researchers are turning to Quadratic.
Quadratic is a next-generation, programmable spreadsheet built to handle complex research workflows. It is specifically tailored for ingesting unstructured sources into standardized formats. Let us look at how one clinical researcher used Quadratic to transform a manual, error-prone workflow into an efficient, automated process.
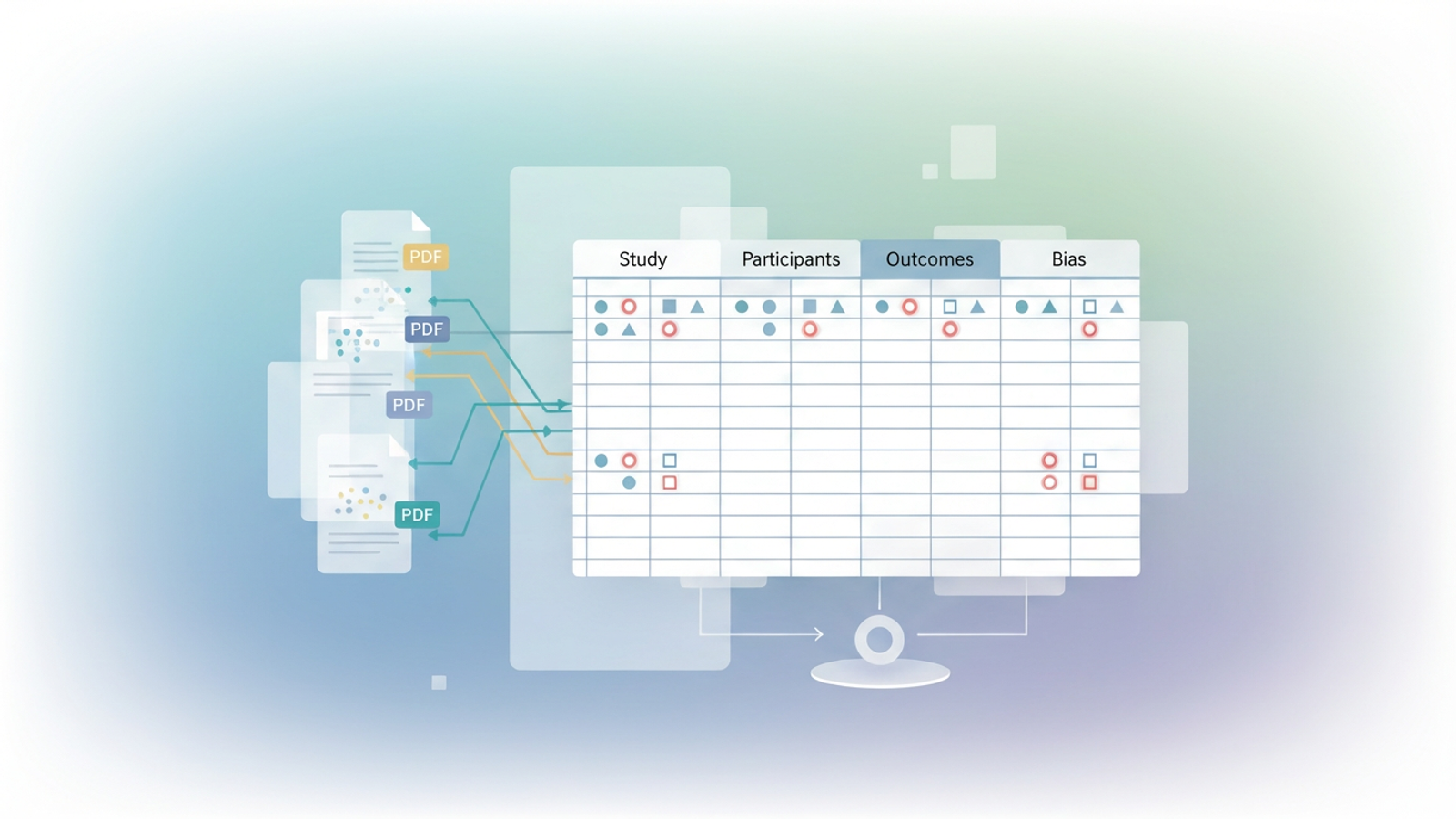
Step 1: setting up the pre-structured environment
The workflow begins by creating a pre-structured environment within Quadratic. The researcher built a multi-tab setup, dedicating individual sheets to specific data categories like Study Characteristics, Participants, Interventions, Outcomes, and Bias. By establishing predefined, standardized column headings in advance, the researcher ensured strict uniformity across dozens of different studies.
Step 2: ingesting unstructured PDF data
The core action involves pulling both quantitative and qualitative data directly from multiple clinical trial PDFs. Using Quadratic's native capabilities, the researcher extracted heterogeneous research data from these unstructured sources directly into the corresponding pre-formatted spreadsheet tabs. This bypasses hours of manual typing and significantly reduces the immediate risk of transcription errors.
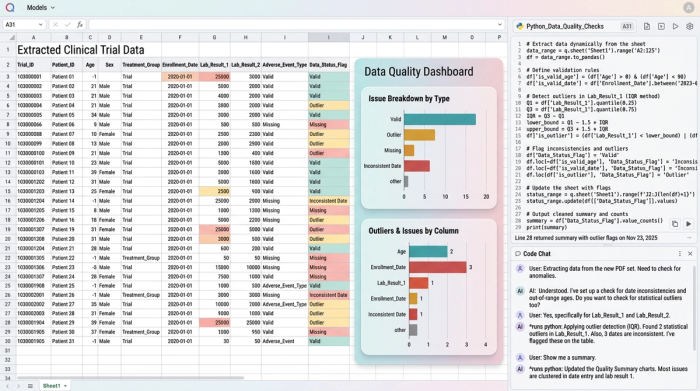
Step 3: flagging inconsistencies and ensuring data quality
Quality and reliability are paramount in systematic evidence synthesis. Inside Quadratic, the researcher utilized the dynamic spreadsheet environment to automatically flag inconsistent values and identify potential extraction errors. Because Quadratic supports Python, SQL, and standard formulas directly in the grid, researchers can build logic to spot missing data, manage outliers, and clean data on the fly. This ensures high-fidelity outputs suitable for rigorous peer review.
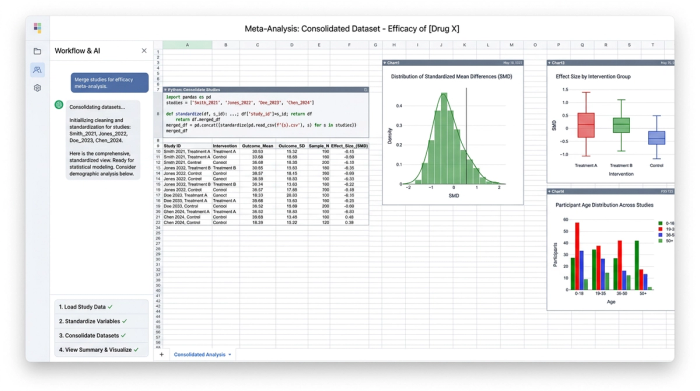
Step 4: consolidating data for meta-analysis preparation
The final step of the workflow is consolidating information from multiple source documents across the various tabs. Quadratic allows for comprehensive comparison and analysis across all ingested studies. This perfectly packages the standardized data for meta-analysis preparation, giving data scientists a clean, structured foundation for their statistical models.
Why next-generation spreadsheets are the future of systematic reviews
Upgrading your tooling does not change the rigorous rules of clinical research. Instead, it simply modernizes the execution, aligning with the principles of data analytics modernization. By moving away from static PDFs and manual entry, researchers can drastically improve clinical data handling. A dynamic, programmable spreadsheet environment reduces human error, saves countless hours, and ultimately elevates the quality and reliability of the final analysis.
Ready to streamline your next systematic review?
Stop letting manual data entry slow down your critical research. Quadratic empowers clinical researchers and data scientists to build automated, multi-tab extraction workflows tailored to their specific protocols. Try Quadratic today to transform how you manage clinical trial data extraction for your next project.
Use Quadratic to streamline clinical trial data extraction
- Directly extract quantitative and qualitative data from clinical trial PDFs into structured, multi-tab spreadsheets.
- Standardize critical study characteristics, participant details, interventions, and outcomes with pre-defined column headings.
- Automatically identify and flag data inconsistencies, missing variables, and errors using integrated Python, SQL, and formulas.
- Consolidate and prepare clean, standardized data from multiple studies for robust meta-analysis and statistical modeling.
Stop letting manual data entry slow down your critical research. See how Quadratic can transform your clinical trial data workflows. Try Quadratic.