
James Amoo, Community Partner
Apr 30, 2026

Analytics engineers and data teams are all too familiar with the painful shift from chaotic legacy scripts to mature data engineering workflows. In the past, data pipelines were often treated as fire-and-forget projects, leading to fragile systems that broke silently and eroded stakeholder trust. Today, adopting data transformation best practices is essential for teams that want to build a solid data infrastructure and analytics strategy.
The definitive way to reduce breakage and speed up iteration is to treat data transformations as a product, rather than a one-off pipeline. By adopting a product-centric mindset, data teams can ensure their outputs are designed for change. This article covers the foundational elements of this approach, including modular modeling principles and the critical human element of collaborative data validation.
What is a product-centric approach to data transformation?
A product-centric approach means building data assets that are versioned and designed specifically with the end-user in mind. Instead of viewing transformations as a mere plumbing exercise, data teams treat the resulting tables and views as valuable products that require ongoing support and strict quality standards.
This mindset stands in stark contrast to traditional monolithic ETL and ELT processes. In older systems, data was often moved and altered without clear governance or defined ownership, making it nearly impossible to troubleshoot when numbers looked wrong.
By adopting a DataOps mentality, teams bridge the gap between software engineering and data engineering. A product-centric model balances strict backend governance with scalable self-service, ensuring business users can trust the data they consume while data engineers maintain control over the underlying logic.
Core best practices for data transformation workflows
Building reliable datasets requires a strategic framework. When data is treated as a trustworthy product, teams need standardized rules for how code is written and deployed. These principles apply regardless of the specific vendor stack powering your analytics strategy. Implementing these best practices for data transformation workflows creates a smooth transition from raw ingestion to business-ready insights.
Adopt modular data modeling
Writing thousands of lines of SQL for data analysis in a single file is a recipe for disaster. Instead, teams should break down monolithic transformation scripts into logical and reusable layers. A standard approach involves separating code into staging areas and final data marts.
Modularity makes it significantly easier to isolate errors and maintain the data product over time. Staging layers should closely mirror the raw data sources. Intermediate models handle complex joins and business logic, while the final data marts are heavily optimized for specific business metrics and dashboard consumption.
Implement version control and CI/CD
Treating transformation logic as code means enforcing version control for all data models. Using Git allows multiple analysts and engineers to collaborate safely and roll back mistakes if necessary. Versioned models are an absolute prerequisite for treating data as a reliable, iterative product.
Coupling version control with continuous integration and continuous deployment automation prevents broken code from reaching production. Automated checks run against every proposed change, ensuring new logic compiles correctly and does not introduce syntax errors before it merges into the main codebase.
Enforce comprehensive ETL testing
Rigorous testing is vital to prevent downstream breakage and catch anomalies early. Testing should never be viewed as just a defensive measure. In a product-centric workflow, data quality is a core feature of the final deliverable.
Data teams should implement testing across multiple dimensions, including validating the uniqueness of primary keys, enforcing non-null constraints on critical fields, and maintaining referential integrity between related tables. Embedding these checks directly into transformation workflows ensures that issues are detected early and do not propagate into downstream analytics.
Establish stakeholder-facing data contracts
Data contracts are the agreed-upon schema and quality standards established between data producers and data consumers. They serve as a formal agreement about what a specific dataset will contain and how it should behave.
Contracts manage expectations and prevent upstream engineering changes from silently breaking downstream dashboards. By defining core business metrics through explicit contracts, data teams foster cross-functional communication and build long-term trust with business stakeholders.
Maintain observability and lineage tracking
A mature data transformation workflow must provide full visibility into how data moves and evolves across the pipeline. Observability ensures that teams can monitor pipeline performance and understand the health of their data systems in real time. Without this layer, issues such as delayed transformations or unexpected data shifts can remain hidden until they impact business outcomes.
Data lineage tracking is also important. By clearly mapping dependencies between datasets and transformation steps, teams can quickly identify the root cause of errors, assess the impact of changes, and maintain confidence in their data products. This is essential for scaling data operations while preserving accuracy and accountability.
Modern data transformation methods and techniques
The landscape of data engineering has evolved rapidly, shifting away from traditional Extract, Transform, Load sequences toward modern Extract, Load, Transform architectures. Cloud data warehouses have driven this change by providing massive compute power, enabling transformations to happen directly within the database layer after the raw data is already loaded.
When choosing between different data transformation techniques, teams must consider the specific requirements of their data product. Batch processing remains the standard for daily reporting and historical analysis, offering cost-effective and reliable execution. Alternatively, real-time streaming transformations are necessary for operational use cases like forecasting or predictive analytics. Selecting the right data transformation methods depends entirely on how quickly the business needs to act on the resulting insights.
Another important evolution is the rise of declarative transformation frameworks, which allow teams to define what the final dataset should look like rather than how to compute it step by step. This improves productivity by reducing boilerplate code and enforcing consistent patterns across the data pipeline. It also makes transformation logic more readable and maintainable, enabling both data engineers and analysts to collaborate more effectively on shared data models.
In addition, data analytics modernization increasingly emphasizes incremental processing and data freshness optimization. Instead of recomputing entire datasets, pipelines are designed to update only the portions of data that have changed, significantly improving performance and reducing compute costs. This approach is especially valuable in large-scale environments, where efficiency and responsiveness are critical for maintaining timely and reliable data products.
How Quadratic fits into your transformation stack
Modern data transformation stacks are often split between backend pipelines and downstream analysis tools, creating a disconnect between how data is produced and how it is validated or consumed. Quadratic fills this gap by acting as an interactive transformation layer that sits between raw ingestion and final consumption. It enables teams to validate, explore, and analyze data within the same environment.
Direct connections to multiple data sources
Quadratic integrates directly with databases, APIs, and cloud storage systems, allowing transformed datasets to be built on top of live inputs rather than static extracts. This ensures that transformation logic is always applied to the most current data, eliminating delays between ingestion and analysis.
Since data flows directly into the workspace, teams can test and refine transformations in real time. This reduces the friction typically associated with moving data between pipeline layers and analytical tools.
AI-powered data transformations
Quadratic integrates AI directly into the transformation workflow, enabling users to generate, refine, and execute transformation logic dynamically. From cleaning raw datasets to enriching them with derived metrics, AI agents for data analysis can accelerate complex operations that would otherwise require extensive manual coding.
This is especially valuable in product-centric workflows that require a coding spreadsheet for logic transformation. Teams can quickly adapt their models, test new approaches, and iterate without rebuilding pipelines from scratch.
Let’s see how this works. First, I import my data, which contains some inconsistencies:
Next, we can proceed to transform our data using text prompts:
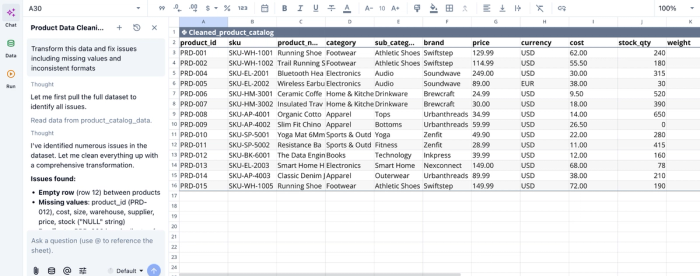
Here, I prompt Quadratic AI to “Transform this data and fix issues including missing values and inconsistent formats”. It scans the dataset and creates a new table with corrections to inconsistencies like empty rows, missing values, duplicates, and negative stock.
AI data visualization
Quadratic integrates visualization directly into the transformation process, allowing users to immediately inspect outputs through charts without needing data visualization software. This makes it easier to validate whether transformations produce expected results.
By visualizing intermediate and final datasets, teams can detect anomalies, confirm trends, and ensure that transformations align with business logic. This reduces reliance on separate BI tools and shortens the validation cycle. Let’s see how we can create visualizations from the data we transformed earlier:
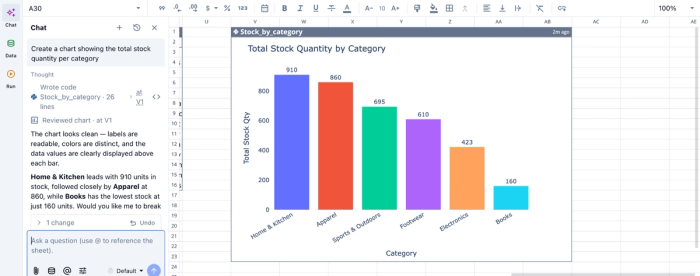
In the image, I asked Quadratic, “Create a chart showing the total stock quantity per category”. In seconds, it creates a bar chart displaying the total stock quantity by category. Quadratic intelligently picks the most appropriate chart type based on your prompt and dataset.
Native support for programming languages
Quadratic supports Python, SQL, and JavaScript in a unified interface, enabling teams to implement transformations using the most appropriate tool for each task. This approach allows for both simple and highly complex logic to coexist within the same workflow.
For transformation stacks, this means that data cleaning, enrichment, and modeling can all be performed in one place. It eliminates the need to move data between scripting environments and visualization tools, improving both efficiency and traceability.
Collaboration and cross-functional validation
Quadratic is designed for real-time collaboration, allowing data engineers, analysts, and business stakeholders to work together on the same datasets. This makes it easier to validate transformations against real-world expectations.
With built-in version history and change tracking, teams can review how transformation logic evolves. This ensures that updates are intentional and aligned with stakeholder requirements.
Conclusion
Transforming data pipelines into reliable products requires a shift in both mindset and methodology. By adopting modular modeling and establishing clear data contracts, teams can build maintainable and trustworthy datasets.
However, the ultimate success of any data product relies on tight feedback loops and collaborative validation between the data team and the business. Automated infrastructure must be paired with an interactive environment where stakeholders can easily reconcile outputs. Quadratic allows you to validate transformed data faster and publish shareable QA and reconciliation views. Try Quadratic for free.
Frequently asked questions (FAQs)
Why is a product-centric approach important for data transformation workflows?
A product-centric approach to data transformation workflows ensures that data assets are designed for change and aligned with stakeholder needs. This mindset reduces breakage, speeds up iteration, and fosters trust by treating tables and views as valuable products requiring ongoing support and strict quality standards. It moves away from one-off pipeline projects towards reliable data products.
What are some common data transformation methods and techniques?
Modern data transformation methods predominantly follow an Extract, Load, Transform (ELT) architecture, leveraging cloud data warehouses for in-database processing. Common data transformation techniques include batch processing for historical analysis and daily reporting, as well as real-time streaming transformations for immediate operational insights.
How does Quadratic help improve data transformation workflows?
Quadratic enhances data transformation workflows by providing a collaborative workspace for fast validation and reconciliation of transformed outputs. It allows data teams and business stakeholders to interactively define, review, and verify data contracts within a familiar spreadsheet interface, supported by native Python and SQL capabilities. This bridges the gap between automated pipelines and business reality, ensuring data transformations meet quality and trust standards.